Bu sene içerisinde kendime belirlediğim yapay zekayı öğrenme hedefinin müthiş keyfli bir alan olduğunu fark ettim. Yazı dizisinin üçüncü kısmında gerçekleştirdiğim platformdan ve entegrasyonlardan bahsedeceğim.
Solarian gibi bir şirketin elindeki en büyük gücü veri ve mühendisliktir. Elimizde tesislerden alnmış IV ölçümleri, sensörlerden alınmış ölçümler, evirici üretim kayıtları gibi zilyon tane veri var. Bu hafta sonu bu veri kaynaklarını otomatik olarak düzenli bir şekilde Influx’a aktarılacak şekilde programladım.
Nasıl mı? Buyrun anlatıyorum.
Türkiye’de yerel GES izleme yazılımcıları eski usul çalışmayı seviyorlar. Nedir bu eski usul? IEC104 haberleşmesi. ModBusTCP gibi bir sunucuya uzaktan ip/port olarak bağlanıp canlı verileri okuyup genel kullanıma uygun (mssql, postgres vb.) bir veri tabanı üzerine kaydediyorlar. Sonra bu verileri işlemek için saatler harcayıp websiteleri tasarlıyorlar. Daha önce bu işi tek kişilik dev kadro olarak grafana ve influxdb ile yapabileceğimizi yazmıştım.
IoT temelinde eski usul scadacılardan farklı olarak verinin push edilmesi daha doğru çünkü uç nokta sayısı çok fazla (hatta belirsiz) ve veri tipleri değişken. Eski usul scadacılarda veri tipleri, adresleri vb. herşey en baştan belirlenir ve sistem tik tak saat gibi ona uygun çalışırdı ama scadalar ve diğer kontrol sistemleri genelde hayati önem taşıyan sistemleri yöneten yazılımlar. IoT ise bambaşka bir durum. Herşeyin saat gibi milimetrik akmasına değil; elde bir veri serisinin olması ve bunun incelenebilmesi önemli. 5-10 dk veri kaybolmuş kaybolmamış kimsenin umrunda değil çünkü tüm grafikler zaten mean() ile yeniden oluşturulan grafikler; kimse kolay kolay ham datayı görmüyor.
Öncelikle veri kaynaklarımı belirledim:
- Datalogger cihazlari
- Meteocontrol/Huawei/Esoft/Inavitas vb. portallar
- IEC104 haberleşmeli Wago vb. türevi cihazlar.
Datalogger cihazlarının (Blue’log, Huawei Smartlogger vb.) FTP push ile gönderdikleri dosyaları parse edip okuyup şuanda veritabanına yazıyorum.
Eski usul scadacıların IEC104 verileri ise “Evde Gerilim!” isimli yazımda anlattığım gibi Kepware aracılığı ile alıp MQTT ile Telegraf üzerinde InfluxDB’ye push ediyorum. O da gayet otomatik bir süreç ki kepware stabilitesi ile tanınır.
Portalların bazıları API sunuyor bazıları sunmuyor. Şuanda API sunanlardan API aracılığı ile veriyi alıp direk InfluxDB’ye yazıyorum. Sunmayanların canı saolsun 🙂 (SQL injection’a karşı açıklar mı denemedim ama muhakkak açıklardır)
Mevcut entegrasyonlar sonucunda şuanda saniyede ~2.300 ölçüm veritabanına her geçen saniye yazılıyor. Bir sene bu hızda gidersem ~200 milyon ölçüm demek ki benim hedefim saniyede 15k-point’e ulaşmak. Bu öngörü ile tamemen SSD üzerinde çalışan bir VPS kiraladım. Şuanda 8-core ile ~2.0 (5min) system-load ile bunun altından kalkabiliyorum (Debian 9). Tabi burada yeterince efektif çalışmayan python kodları var. Kodlaması kolay olsun diye arada işimi hızlandırıcı framework’ler kullanıyorum ki xml->influx yapmak yerine xml->text->data dictonary->json->text->influxdb gibi bazı dönüşümler var. İleride bu kısmı kesinlikle python’dan golang’a taşıyacağım ve aradaki yavaşlatıcı framework’leri kaldıracağım. Bunun %100’den fazla performans artışına yol açacağını öngörüyorum.
Teknik olarak baktığımızda bu altyapı bir GES izleme firmasının sunduğu altyapı ile aynı. Tek farkı bunu benim tek başıma ve açık kaynak kodlu yazılımlar kullanarak yapabiliyor olmam. Türkiye’de pek çok GES izleme firmasında bir yazılımcı ordusu çalışıyor.
Hemen minik bir dashboard yaparak bir GES’i izleyelim.
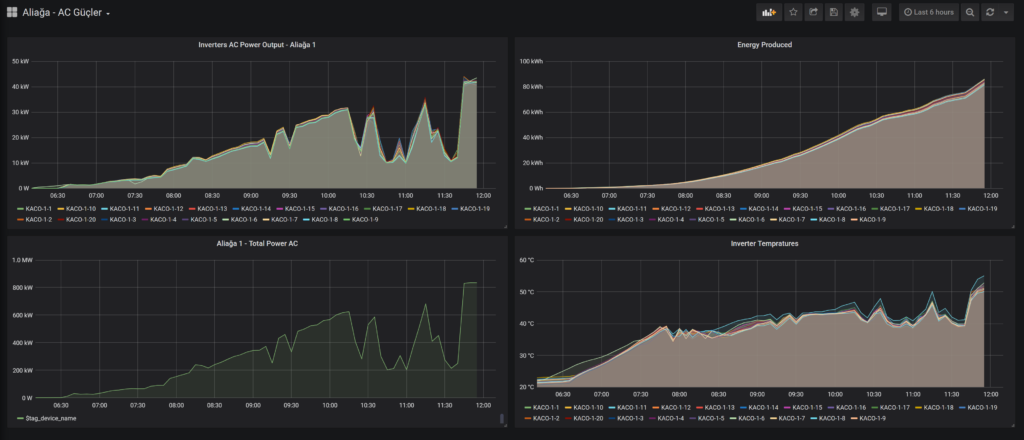
Yukarıda gördüğünüz her GES izleme sisteminin standart ekranlarından; güç, akım, gerilim vs.
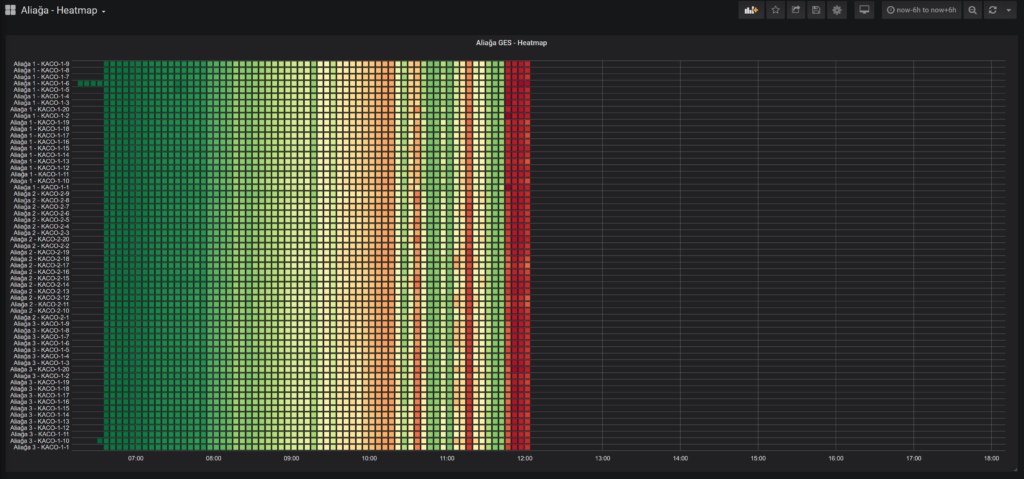
Yukarıdaki ise bugüne kadar Türkiye’de sadece 2 adet izleme sisteminde gördüğüm heatmap ki biz santralleri izlediğimiz yeni hizmet paketimizde en çok bu grafik türünü tercih ediyoruz.
Tabi bu altyapıyı Türkiye’de izleme sistemi satmak için kurmadım o sebeple bu detaylara çok takılmadan esas konumuza dönelim; makine öğrenmesi ve AI.
Burada python ML kodumuzu influx’a bağlayabiliyoruz. Influx sorguları direk olarak pandas datasetine çekilebiliyor. Daha önceden şirket içerisinde kullandığımız hesaplama metodlarına verileri çok hızlı bir şekilde alabiliyoruz. Bazen Keras/Sklearn’ı keşke Influx üzerinde çalıştırabilseydim diye düşünüyorum ama sonra düşüncemin hatasını anlıyorum; gelecek micro-service’lerin geleceği. Tek bir şey yap, en iyisini yap. Influx’ın golang ile yazılma sebeplerinden birisi de bu; en hızlı timeseries-database.
Şuanda hesaplamaları (linear regression, naive bayes, k-means clustering vb.) sunucu üzerinde Python ile yaptırıp yine Influx’ın ayrı bir measurement(table)’ına yazıp çekebiliyoruz. İstatistiki hesaplamaları ise influx’ın iç fonksiyonları ile yapabiliyoruz.
Şimdi bu kadar şeyi yaptın da elinde ne var diyeceksiniz? Sizleri Mimar Sinan’ın Süleymaniye Camii’nin 7 senede inşa edilmesi ile ilgili hikayeyi okumaya davet ediyorum. Bir yapının temelleri ne kadar sağlam ve iyi düşünülmüş olursa üstüne çıkmak o kadar kolay olur. Eğer tüm ekibin kolaylıkla kullanabileceği ve gelecek ekiplere aktarılabilir bir data-warehouse’u kurabilirsem üzerinde yapacağım çalışmalar ile çok hızlı yol alabilirim. Bu data-warehourse gelecekte yatırım kararlarından enerji piyasasında al-sat kararlarına kadar pek çok analizi besleyebilir.
Temmuz’a geldik; Ocak 2019’da başlamıştım. Hala kendimi tamamen veremedim bu projeye ama ayırdığım her vakitten çok keyif alıyorum. Sene sonuna doğru Solarian Analytics adını verdiğim bu projeyi tamamen devreye almayı planlıyorum.
Dizinin bir sonraki makalesinde görüşmek üzere !
Bir yanıt yazın